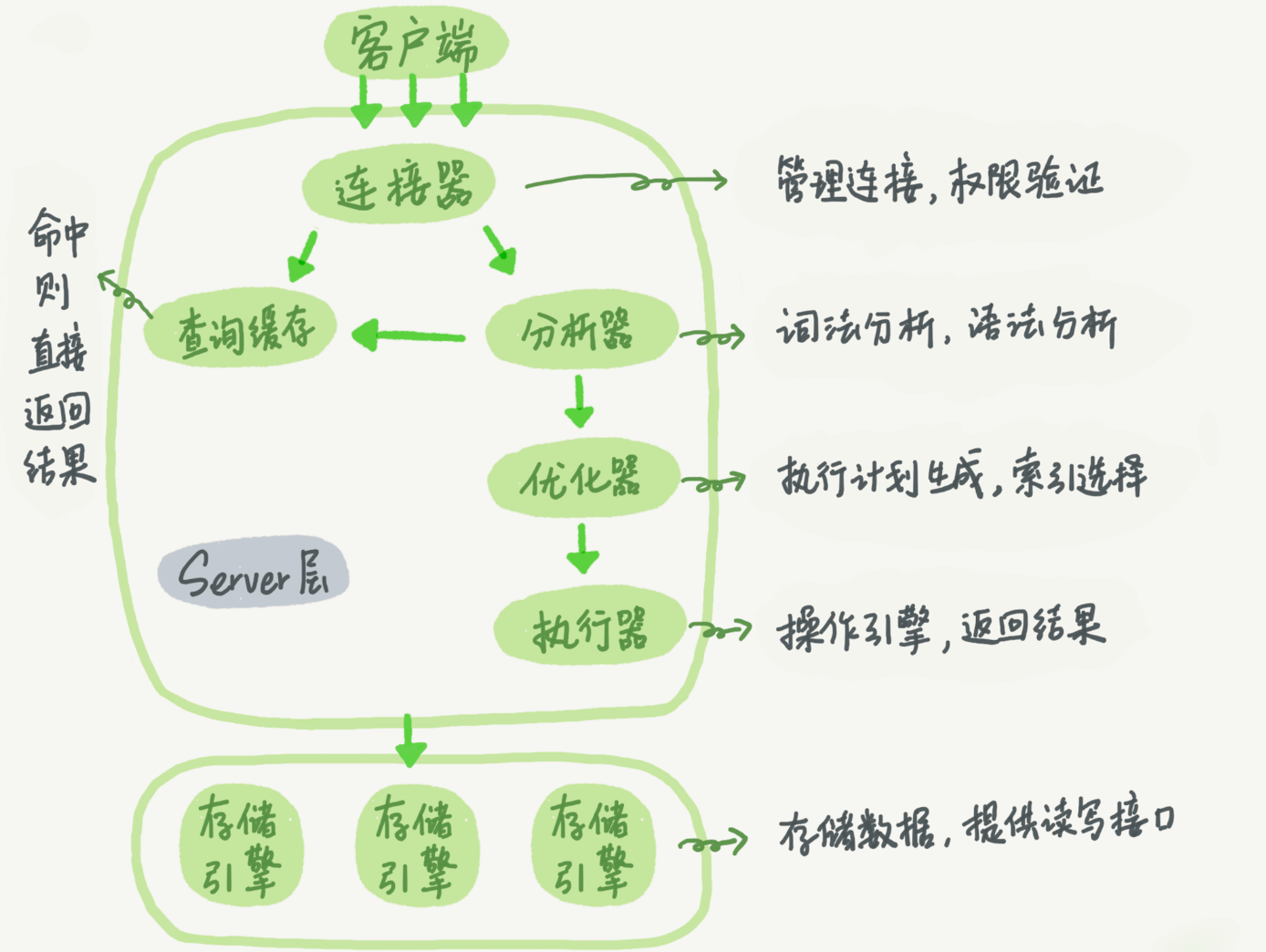
SQL 执行过程
为什么使用 B+ 数
一句话,主要是为了更好的性能。B+ 数只有叶子节点存储数据,其他节点存储的是索引;
因为 MySQL 是以页为基本单位读取数据的,同时 B+ 树中的节点大小也是页,B+ 树非叶子节点用来存放索引而不是实际的业务数据,所以每页(每个节点)可以存储更多条记录,所以树的高度更低,所以查询数据需要的磁盘 IO 更少。
什么是索引
索引是 MySQL 为了加快查询速度生成的数据结构,利用空间换时间,每一个索引都对应一颗 B+ 树。
索引的缺点是占用磁盘空间、降低数据更新性能。
参考:https://zhuanlan.zhihu.com/p/481750465
索引有几种类型
- 聚簇索引(一级索引)
- 主键索引
- 非聚簇索引(二级索引)
- 普通索引
- 唯一索引
- 联合索引
- 全文索引
什么是前缀索引
前缀索引能有效减小索引文件的大小,让每个索引页可以保存更多的索引值,从而提高了索引查询的速度。但前缀索引也有它的缺点,不能在 order by 或者 group by 中触发前缀索引,也不能把它们用于覆盖索引。
参考:https://blog.51cto.com/u_15311952/3186968
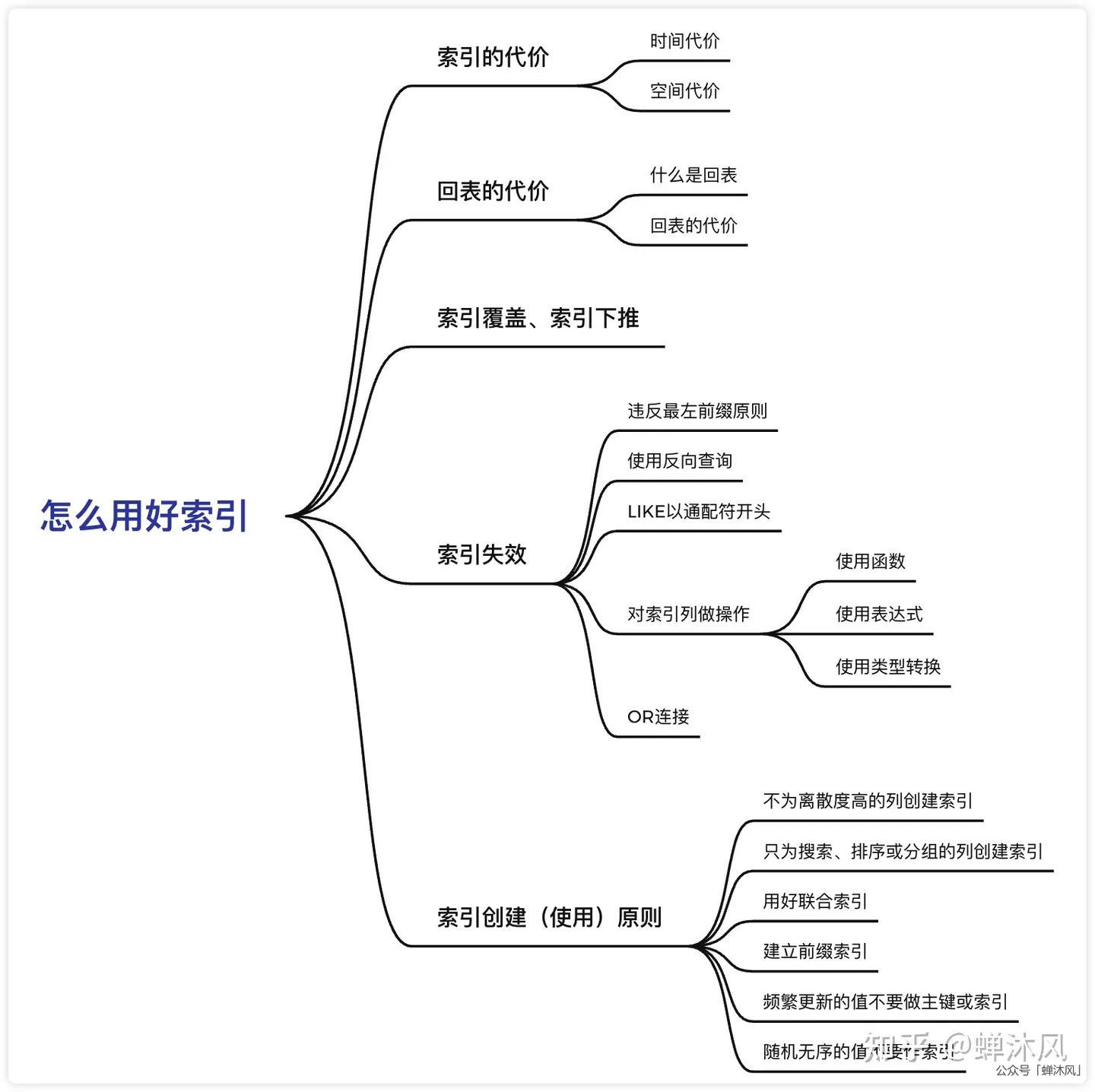
创建索引的原则
给 where 后面经常用到的字段加索引
数据量很小的表可以不创建索引,可能会变慢
列值重复度高的不要创建索引,没效果
索引的数量不要太多,建议 3-5 个
索引尽量的短,可以使 B+ 树节点存储更多的索引量
可以长度很长的列值创建前缀索引
参考:https://www.jianshu.com/p/fc80445044cc
什么情况下索引失效
- 违反最左前缀匹配原则,如组合索引 idx_name_phone,where phone=12345 不用索引,where name=”abc”使用了索引,where name=”abc”and phone=12345 也使用索引。
- 使用反向查询(≠ 、<>、not like)
- 使用 like“%abc”这种查询条件,但是 like“abc%”不影响。
- 使用
OR连接的查询语句,如果OR之前的条件列是索引列,但是OR之后的条件列不是索引列,则不会使用索引。 - 对索引列使用函数、计算、类型转换等操作
什么是回表
如果索引的列在 select 所需获得的列中(因为在 mysql 中索引是根据索引列的值进行排序的,所以索引节点中存在该列中的部分值)或者根据一次索引查询就能获得记录就不需要回表,如果 select 所需获得列中有大量的非索引列,索引就需要到表中找到相应的列的信息,这就叫回表。
什么是索引覆盖
查询的字段包含在索引里面,不需要回表,称为索引覆盖。
只需要在一棵索引树上就能获取 SQL 所需的所有列数据,无需回表,速度更快。
explain 的输出结果 Extra 字段为 Using index 时,能够触发索引覆盖。
MySQL 的锁机制
锁和索引关系密切。update 默认开启事务,根据 where 条件决定
有索引的情况下:
行锁:锁住要更新的 1 行或多行,比如 id > xx
- 记录锁:对存在的行加锁。
- 间隙锁:对不存在的行加锁。
- 临建锁:可能会锁住一些不存在的行,比如数据库里只有 ID=101,ID=105,ID=106 的行,但是执行的是 where id > 100,此时对 ID=200,ID=102 等的行插入也是不行的。
没索引的情况下:
修改表结构会使用表锁,所有增删改查都需要等待。
表锁:如果没用到索引,则行锁会升级为表锁
为什么建议数据库要有主键
为了方便数据存储和查询,如果没有主键,MySQL 默认会使用一个 rowid 代替,但是这个 rowid 达到上限后会从 0 开始,再插入数据会导致原来的数据记录被覆盖,所以不安全。
如果指定了一个主键 ID,同样达到上限后,再次插入会报错但不会覆盖数据,业务上更安全。
一般 int 上限是 2^32=42 亿,如果换成 big int,会是 2^64=无穷大。
如果考虑到以后会分库分表,不建议使用自增主键,建议使用雪花算法生成主键 ID。
为什么删除了数据磁盘文件大小不变
首先,MySQL 数据是按页存储的,因为 MySQL 删除数据只是给数据一个已删除的标记,并不会真正删除数据。
MySQL 数据碎片
数据碎片主要是因为 MySQL 删除数据后导致的数据空洞,可以通过重新建表的方式消除。
如果数据库里本身没有空洞,执行重新建表后,可能会使存储空间变大,原因是每页中除了数据外,还要存储其他的信息。
脏读 & 幻读
脏读又称无效数据的读出,是指在数据库访问中,事务 T1 将某一值修改,然后事务 T2 读取该值,此后 T1 因为某种原因撤销对该值的修改,这就导致了 T2 所读取到的数据是无效的,值得注意的是,脏读一般是针对于 update 操作的。
不可重复读 是指 A 事务开始时读取一个结果 N,中间因为另一个事务 B 又提交了数据,导致 A 事务再次读取时拿到结果 N‘ ,造成前后数据不一致,这种称为不可重复读。